
Autoregressive pre-training has proved to be revolutionary in machine studying, particularly regarding sequential information processing. Predictive modeling of the next sequence components has been extremely efficient in pure language processing and, more and more, has been explored inside laptop imaginative and prescient domains. Video modeling is one space that has hardly been explored, giving alternatives for extending into motion recognition, object monitoring, and robotics functions. These developments are resulting from rising datasets and innovation in transformer architectures that deal with visible inputs as structured tokens appropriate for autoregressive coaching.
Modeling movies has distinctive challenges resulting from their temporal dynamics and redundancy. In contrast to textual content with a transparent sequence, video frames normally comprise redundant data, making it tough to tokenize and study correct representations. Correct video modeling ought to be capable of overcome this redundancy whereas capturing spatiotemporal relationships in frames. Most frameworks have centered on image-based representations, leaving the optimization of video architectures open. The duty requires new strategies to stability effectivity and efficiency, notably when video forecasting and robotic manipulation are at play.
Visible illustration studying by way of convolutional networks and masked autoencoders has been efficient for picture duties. Such approaches sometimes fail relating to video functions as they can not solely categorical temporal dependencies. Tokenization strategies similar to dVAE and VQGAN usually convert visible data into tokens. These have proven effectiveness, however scaling such an method turns into difficult in situations with combined datasets involving photos and movies. Patch-based tokenization doesn’t generalize to cater to varied duties effectively in a video.
A analysis staff from Meta FAIR and UC Berkeley has launched the Toto household of autoregressive video fashions. Their novelty is to assist deal with the restrictions of conventional strategies, treating movies as sequences of discrete visible tokens and making use of causal transformer architectures to foretell subsequent tokens. The researchers developed fashions that would simply mix picture and video coaching by coaching on a unified dataset that features multiple trillion tokens from photos and movies. The unified method enabled the staff to reap the benefits of the strengths of autoregressive pretraining in each domains.
The Toto fashions use dVAE tokenization with an 8k-token vocabulary to course of photos and video frames. Every body is resized and tokenized individually, leading to sequences of 256 tokens. These tokens are then processed by a causal transformer that makes use of the options of RMSNorm and RoPE embeddings to determine improved mannequin efficiency. The coaching was performed on ImageNet and HowTo100M datasets, tokenizing at a decision of 128×128 pixels. The researchers additionally optimized the fashions for downstream duties by changing common pooling with consideration pooling to make sure a greater high quality of illustration.
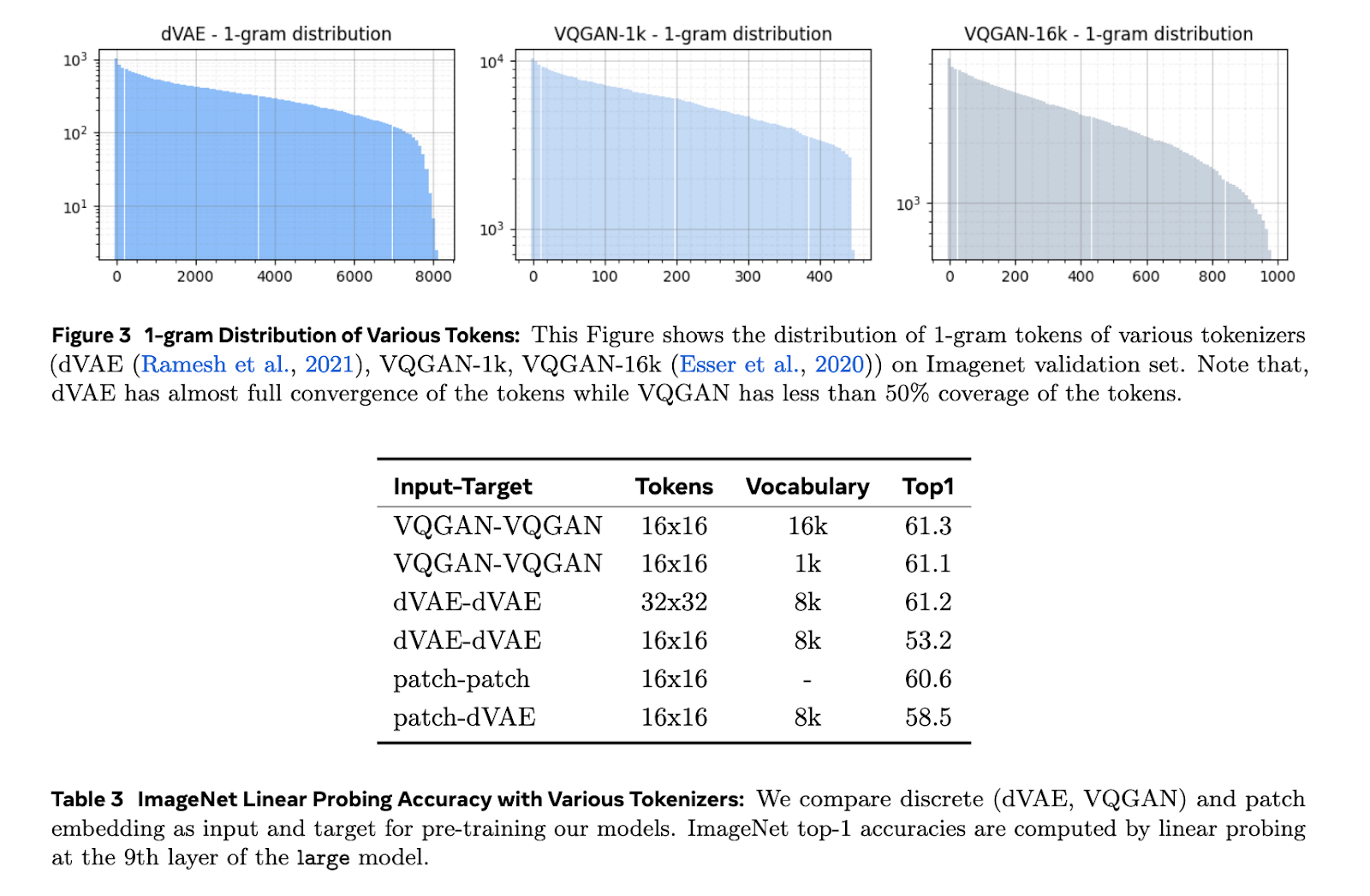
The fashions present good efficiency throughout the benchmarks. For ImageNet classification, the biggest Toto mannequin achieved a top-1 accuracy of 75.3%, outperforming different generative fashions like MAE and iGPT. Within the Kinetics-400 motion recognition job, the fashions obtain a top-1 accuracy of 74.4%, proving their functionality to know advanced temporal dynamics. On the DAVIS dataset for semi-supervised video monitoring, the fashions get hold of J&F scores of as much as 62.4, thus enhancing over earlier state-of-the-art benchmarks established by DINO and MAE. Furthermore, on robotics duties like object manipulation, Toto fashions study a lot sooner and are extra pattern environment friendly. For instance, the Toto-base mannequin attains a cube-picking real-world job on the Franka robotic with an accuracy of 63%. Total, these are spectacular outcomes relating to the flexibility and scalability of those proposed fashions with numerous functions.

The work supplied important growth in video modeling by addressing redundancy and challenges in tokenization. The researchers efficiently confirmed “by unified coaching on each photos and movies, that this type of autoregressive pretraining is mostly efficient throughout a spread of duties.” Revolutionary structure and tokenization methods present a baseline for additional dense prediction and recognition analysis. That is one significant step towards unlocking the total potential of video modeling in real-world functions.
Take a look at the Paper and Mission Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 65k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Information and Analysis Intelligence–Be part of this webinar to realize actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding information privateness.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


{kind=link}