: A Novel Publish-Coaching Quantization Technique Designed to Improve the Effectivity of Giant Language Fashions (LLMs)")
Publish-training quantization (PTQ) focuses on decreasing the dimensions and bettering the velocity of enormous language fashions (LLMs) to make them extra sensible for real-world use. Such fashions require giant information volumes, however strongly skewed and extremely heterogeneous information distribution throughout quantization presents appreciable difficulties. This is able to inevitably develop the quantization vary, making it, in most values, a much less correct expression and decreasing basic efficiency in mannequin precision. Whereas PTQ strategies intention to deal with these points, challenges stay in successfully distributing information throughout the complete quantization area, limiting the potential for optimization and hindering broader deployment in resource-constrained environments.
Present Publish-training quantization (PTQ) strategies of enormous language fashions (LLMs) give attention to weight-only and weight-activation quantization. Weight-only strategies, comparable to GPTQ, AWQ, and OWQ, try to cut back reminiscence utilization by minimizing quantization errors or addressing activation outliers however fail to optimize precision for all values absolutely. Methods like QuIP and QuIP# use random matrices and vector quantization however stay restricted in dealing with excessive information distributions. Weight-activation quantization goals to hurry up inference by quantizing each weights and activations. But, strategies like SmoothQuant, ZeroQuant, and QuaRot wrestle to handle the dominance of activation outliers, inflicting errors in most values. General, these strategies depend on heuristic approaches and fail to optimize information distribution throughout the complete quantization area, which limits efficiency and effectivity.
To deal with the constraints of heuristic post-training quantization (PTQ) strategies and the dearth of a metric for assessing quantization effectivity, researchers from the Houmo AI, Nanjing College, and Southeast College proposed the Quantization House Utilization Fee (QSUR) idea. QSUR measures how successfully weight and activation distributions make the most of the quantization area, providing a quantitative foundation to judge and enhance PTQ strategies. The metric leverages statistical properties like eigenvalue decomposition and confidence ellipsoids to calculate the hypervolume of weight and activation distributions. QSUR evaluation exhibits how linear and rotational transformations have an effect on quantization effectivity, with particular strategies decreasing inter-channel disparities and minimizing outliers to reinforce efficiency.
Researchers proposed the OSTQuant framework, which mixes orthogonal and scaling transformations to optimize giant language fashions’ weight and activation distributions. This strategy integrates learnable equal transformation pairs of diagonal scaling and orthogonal matrices, guaranteeing computational effectivity whereas preserving equivalence at quantization. It reduces overfitting with out compromising the output of the unique community on the time of inference. OSTQuant makes use of inter-block studying to propagate transformations globally throughout LLM blocks, using strategies like Weight Outlier Minimization Initialization (WOMI) for efficient initialization. The strategy achieves increased QSUR, reduces runtime overhead, and enhances quantization efficiency in LLMs.
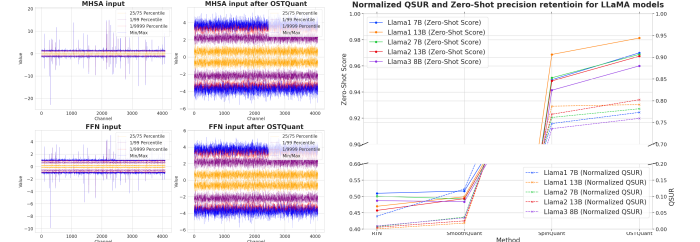
For analysis functions, researchers utilized OSTQuant to the LLaMA household (LLaMA-1, LLaMA-2, and LLaMA-3) and assessed efficiency utilizing perplexity on WikiText2 and 9 zero-shot duties. In comparison with strategies like SmoothQuant, GPTQ, Quarot, and SpinQuant, OSTQuant constantly outperformed them, attaining no less than 99.5% floating-point accuracy below the 4-16-16 setup and considerably narrowing efficiency gaps. LLaMA-3-8B incurred solely a 0.29-point drop in zero-shot duties, in comparison with losses exceeding 1.55 factors for others. In tougher eventualities, OSTQuant was higher than SpinQuant and gained as a lot as 6.53 factors by LLaMA-2 7B within the 4-4-16 setup. The KL-High loss perform offered a greater becoming of semantics and lowered noise, thus enhancing efficiency and decreasing gaps within the W4A4KV4 by 32%. These outcomes confirmed that OSTQuant is more practical at outlier dealing with and making certain distributions are extra unbiased.

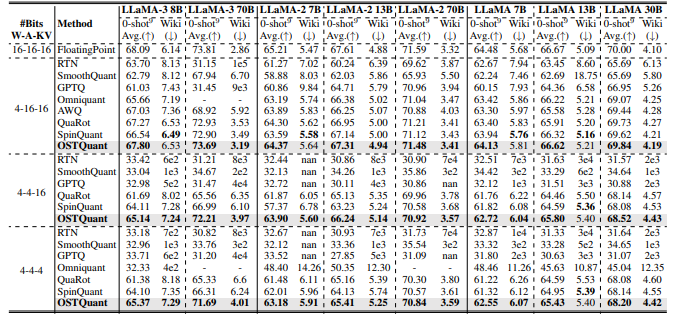
Ultimately, the proposed technique optimized the info distributions within the quantization area primarily based on the QSUR metric and the loss perform, KL-High, bettering the efficiency of enormous language fashions. With low calibration information, it diminished noise and preserved semantic richness in comparison with present quantization strategies, attaining excessive efficiency in a number of benchmarks. This framework can function a foundation for future work, beginning a course of that shall be instrumental in perfecting quantization strategies and making fashions extra environment friendly for purposes requiring excessive computation effectivity in resource-constrained settings.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with imaginative and prescient fashions, new language fashions, embeddings and LoRA (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.


{kind=link}