
Toyota Analysis Institute Researchers have unveiled Multi-View Geometric Diffusion (MVGD), a groundbreaking diffusion-based structure that instantly synthesizes high-fidelity novel RGB and depth maps from sparse, posed photos, bypassing the necessity for express 3D representations like NeRF or 3D Gaussian splats. This innovation guarantees to redefine the frontier of 3D synthesis by providing a streamlined, sturdy, and scalable resolution for producing reasonable 3D content material.
The core problem MVGD addresses is attaining multi-view consistency: making certain generated novel viewpoints seamlessly combine in 3D house. Conventional strategies depend on constructing complicated 3D fashions, which regularly endure from reminiscence constraints, gradual coaching, and restricted generalization. MVGD, nevertheless, integrates implicit 3D reasoning instantly right into a single diffusion mannequin, producing photos and depth maps that keep scale alignment and geometric coherence with enter photos with out intermediate 3D mannequin building.
MVGD leverages the facility of diffusion fashions, recognized for his or her high-fidelity picture technology, to encode look and depth info concurrently
Key progressive parts embrace:
Pixel-Degree Diffusion: In contrast to latent diffusion fashions, MVGD operates at authentic picture decision utilizing a token-based structure, preserving high-quality particulars.
Joint Activity Embeddings: A multi-task design permits the mannequin to collectively generate RGB photos and depth maps, leveraging a unified geometric and visible prior.
Scene Scale Normalization: MVGD mechanically normalizes scene scale based mostly on enter digital camera poses, making certain geometric coherence throughout numerous datasets.
Coaching on an unprecedented scale, with over 60 million multi-view picture samples from real-world and artificial datasets, empowers MVGD with distinctive generalization capabilities. This large dataset permits:
Zero-Shot Generalization: MVGD demonstrates sturdy efficiency on unseen domains with out express fine-tuning.
Robustness to Dynamics: Regardless of not explicitly modeling movement, MVGD successfully handles scenes with shifting objects.
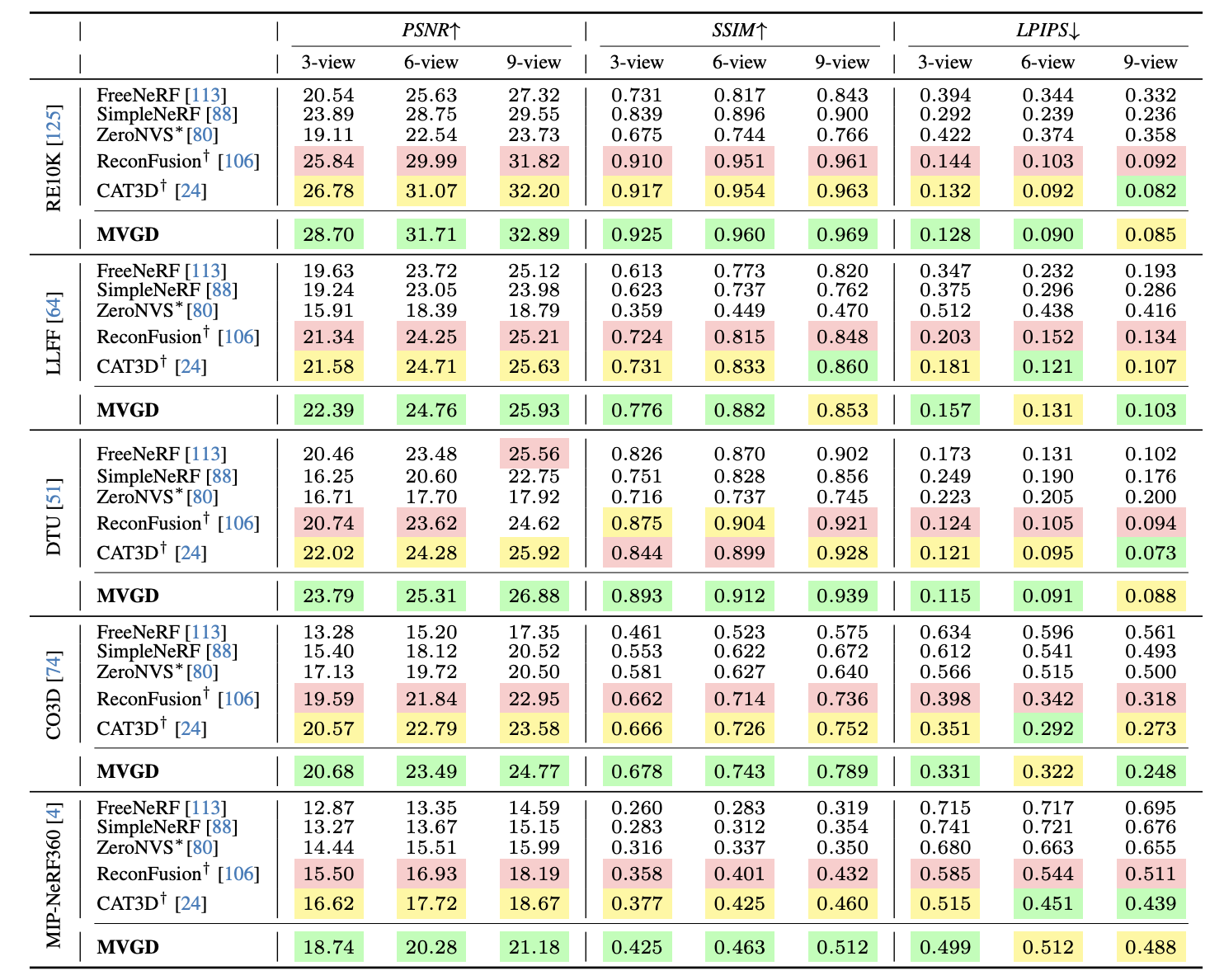
MVGD achieves state-of-the-art efficiency on benchmarks like RealEstate10K, CO3Dv2, and ScanNet, surpassing or matching present strategies in each novel view synthesis and multi-view depth estimation.
MVGD introduces incremental conditioning and scalable fine-tuning, enhancing its versatility and effectivity.
Incremental conditioning permits for refining generated novel views by feeding them again into the mannequin.
Scalable fine-tuning permits incremental mannequin enlargement, boosting efficiency with out in depth retraining.
The implications of MVGD are important:
Simplified 3D Pipelines: Eliminating express 3D representations streamlines novel view synthesis and depth estimation.
Enhanced Realism: Joint RGB and depth technology supplies lifelike, 3D-consistent novel viewpoints.
Scalability and Adaptability: MVGD handles various numbers of enter views, essential for large-scale 3D seize.
Speedy Iteration: Incremental fine-tuning facilitates adaptation to new duties and complexities.
MVGD represents a big leap ahead in 3D synthesis, merging diffusion class with sturdy geometric cues to ship photorealistic imagery and scale-aware depth. This breakthrough alerts the emergence of “geometry-first” diffusion fashions, poised to revolutionize immersive content material creation, autonomous navigation, and spatial AI.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 80k+ ML SubReddit.
🚨 Beneficial Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Information Compliance Requirements to Deal with Authorized Issues in AI Datasets

Jean-marc is a profitable AI enterprise government .He leads and accelerates progress for AI powered options and began a pc imaginative and prescient firm in 2006. He’s a acknowledged speaker at AI conferences and has an MBA from Stanford.


{kind=link}