
Understanding lengthy movies, akin to 24-hour CCTV footage or full-length movies, is a significant problem in video processing. Massive Language Fashions (LLMs) have proven nice potential in dealing with multimodal knowledge, together with movies, however they wrestle with the large knowledge and excessive processing calls for of prolonged content material. Most present strategies for managing lengthy movies lose important particulars, as simplifying the visible content material usually removes delicate but important data. This limits the flexibility to successfully interpret and analyze complicated or dynamic video knowledge.
Strategies at present used to know lengthy movies embrace extracting key frames or changing video frames into textual content. These strategies simplify processing however lead to an enormous lack of data since delicate particulars and visible nuances are omitted. Superior video LLMs, akin to Video-LLaMA and Video-LLaVA, try to enhance comprehension utilizing multimodal representations and specialised modules. Nevertheless, these fashions require intensive computational sources, are task-specific, and wrestle with lengthy or unfamiliar movies. Multimodal RAG techniques, like iRAG and LlamaIndex, improve knowledge retrieval and processing however lose useful data when remodeling video knowledge into textual content. These limitations forestall present strategies from totally capturing and using the depth and complexity of video content material.
To handle the challenges of video understanding, researchers from Om AI Analysis and Binjiang Institute of Zhejiang College launched OmAgent, a two-step strategy: Video2RAG for preprocessing and DnC Loop for process execution. In Video2RAG, uncooked video knowledge undergoes scene detection, visible prompting, and audio transcription to create summarized scene captions. These captions are vectorized and saved in a data database enriched with additional specifics about time, location, and occasion particulars. On this approach, the method avoids massive context inputs to language fashions and, therefore, issues akin to token overload and inference complexity. For process execution, queries are encoded, and these video segments are retrieved for additional evaluation. This ensures environment friendly video understanding by balancing detailed knowledge illustration and computational feasibility.
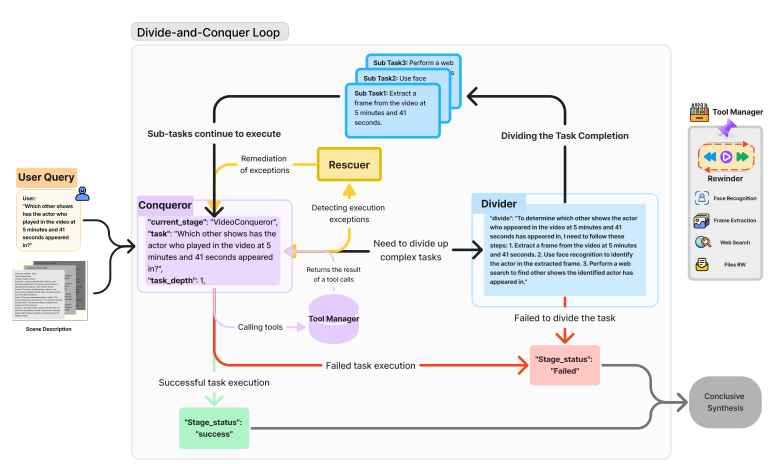
The DNC Loop employs a divide-and-conquer technique, recursively decomposing duties into manageable subtasks. The Conqueror module evaluates duties, directing them for division, instrument invocation, or direct decision. The Divider module breaks up complicated duties, and the Rescuer offers with execution errors. The recursive process tree construction helps within the efficient administration and backbone of duties. The mixing of structured preprocessing by Video2RAG and the strong framework of DnC Loop makes OmAgent ship a complete video understanding system that may deal with intricate queries and produce correct outcomes.
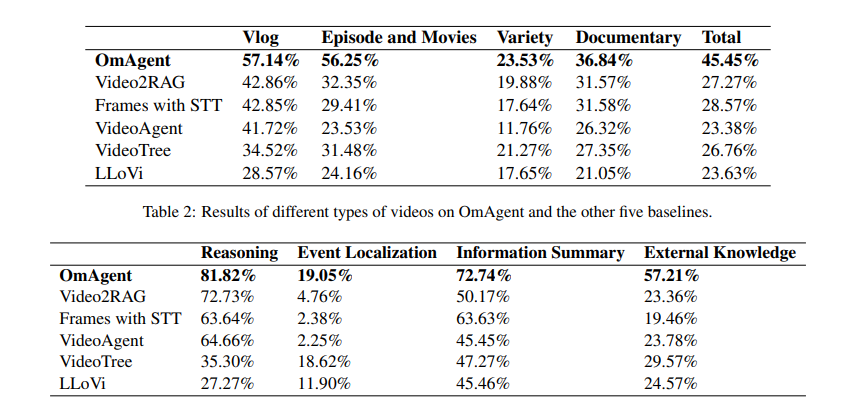
Researchers carried out experiments to validate OmAgent’s skill to unravel complicated issues and comprehend long-form movies. They used two benchmarks, MBPP (976 Python duties) and FreshQA (dynamic real-world Q&A), to check normal problem-solving, specializing in planning, process execution, and power utilization. They designed a benchmark with over 2000 Q&A pairs for video understanding primarily based on various lengthy movies, evaluating reasoning, occasion localization, data summarization, and exterior data. OmAgent constantly outperformed baselines throughout all metrics. In MBPP and FreshQA, OmAgent achieved 88.3% and 79.7%, respectively, surpassing GPT-4 and XAgent. OmAgent scored 45.45% total for video duties in comparison with Video2RAG (27.27%), Frames with STT (28.57%), and different baselines. It excelled in reasoning (81.82%) and knowledge abstract (72.74%) however struggled with occasion localization (19.05%). OmAgent’s Divide-and-Conquer (DnC) Loop and rewinder capabilities considerably improved efficiency in duties requiring detailed evaluation, however precision in occasion localization remained difficult.
In abstract, the proposed OmAgent integrates multimodal RAG with a generalist AI framework, enabling superior video comprehension with near-infinite understanding capability, a secondary recall mechanism, and autonomous instrument invocation. It achieved robust efficiency on a number of benchmarks. Whereas challenges like occasion positioning, character alignment, and audio-visual asynchrony stay, this methodology can function a baseline for future analysis to enhance character disambiguation, audio-visual synchronization, and comprehension of nonverbal audio cues, advancing long-form video understanding.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 Suggest Open-Supply Platform: Parlant is a framework that transforms how AI brokers make selections in customer-facing eventualities. (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.


{kind=link}