
Researchers are focusing more and more on creating programs that may deal with multi-modal information exploration, which mixes structured and unstructured information. This entails analyzing textual content, photographs, movies, and databases to reply advanced queries. These capabilities are essential in healthcare, the place medical professionals work together with affected person information, medical imaging, and textual studies. Equally, multi-modal exploration helps interpret databases with metadata, textual critiques, and art work photographs in artwork curation or analysis. Seamlessly combining these information sorts gives important potential for decision-making and insights.
One of many principal challenges on this discipline is enabling customers to question multi-modal information utilizing pure language. Conventional programs wrestle to interpret advanced queries that contain a number of information codecs, corresponding to asking for developments in structured tables whereas analyzing associated picture content material. Furthermore, the absence of instruments that present clear explanations for question outcomes makes it tough for customers to belief and validate the outcomes. These limitations create a niche between superior information processing capabilities and real-world usability.
Present options try to handle these challenges utilizing two principal approaches. The primary integrates a number of modalities into unified question languages, corresponding to NeuralSQL, which embeds vision-language capabilities instantly into SQL instructions. The second makes use of agentic workflows that coordinate varied instruments for analyzing particular modalities, exemplified by CAESURA. Whereas these approaches have superior the sphere, they fall brief in optimizing process execution, making certain explainability, and addressing advanced queries effectively. These shortcomings spotlight the necessity for a system able to dynamic adaptation and clear reasoning.
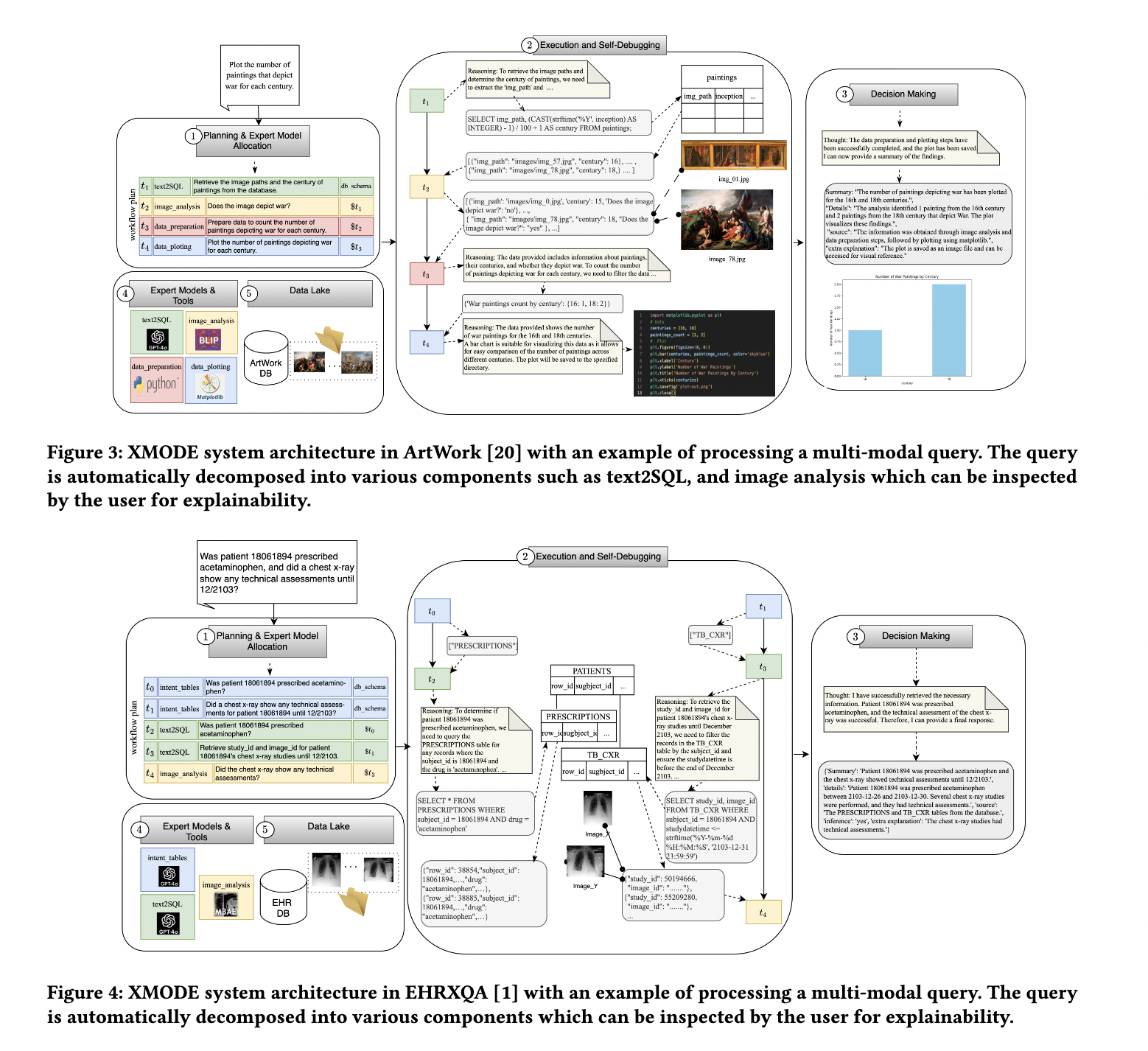
Researchers at Zurich College of Utilized Sciences have launched XMODE, a novel system designed to handle these points. XMODE allows explainable multi-modal information exploration utilizing a Massive Language Mannequin (LLM)-based agentic framework. The system interprets person queries and decomposes them into subtasks like SQL technology and picture evaluation. By creating workflows represented as Directed Acyclic Graphs (DAGs), XMODE optimizes the sequence and execution of duties. This strategy improves effectivity and accuracy in comparison with state-of-the-art programs like CAESURA and NeuralSQL. Furthermore, XMODE helps process re-planning, enabling it to adapt when particular elements fail.
The structure of XMODE contains 5 key elements: planning and knowledgeable mannequin allocation, execution and self-debugging, decision-making, knowledgeable instruments, and a shared information repository. When a question is obtained, the system constructs an in depth workflow of duties, assigning them to applicable instruments like SQL technology modules and picture evaluation fashions. These duties are executed in parallel wherever doable, lowering latency and computational prices. Additional, XMODE’s self-debugging capabilities permit it to establish and rectify errors in process execution, making certain reliability. This adaptability is vital for dealing with advanced workflows that contain numerous information modalities.
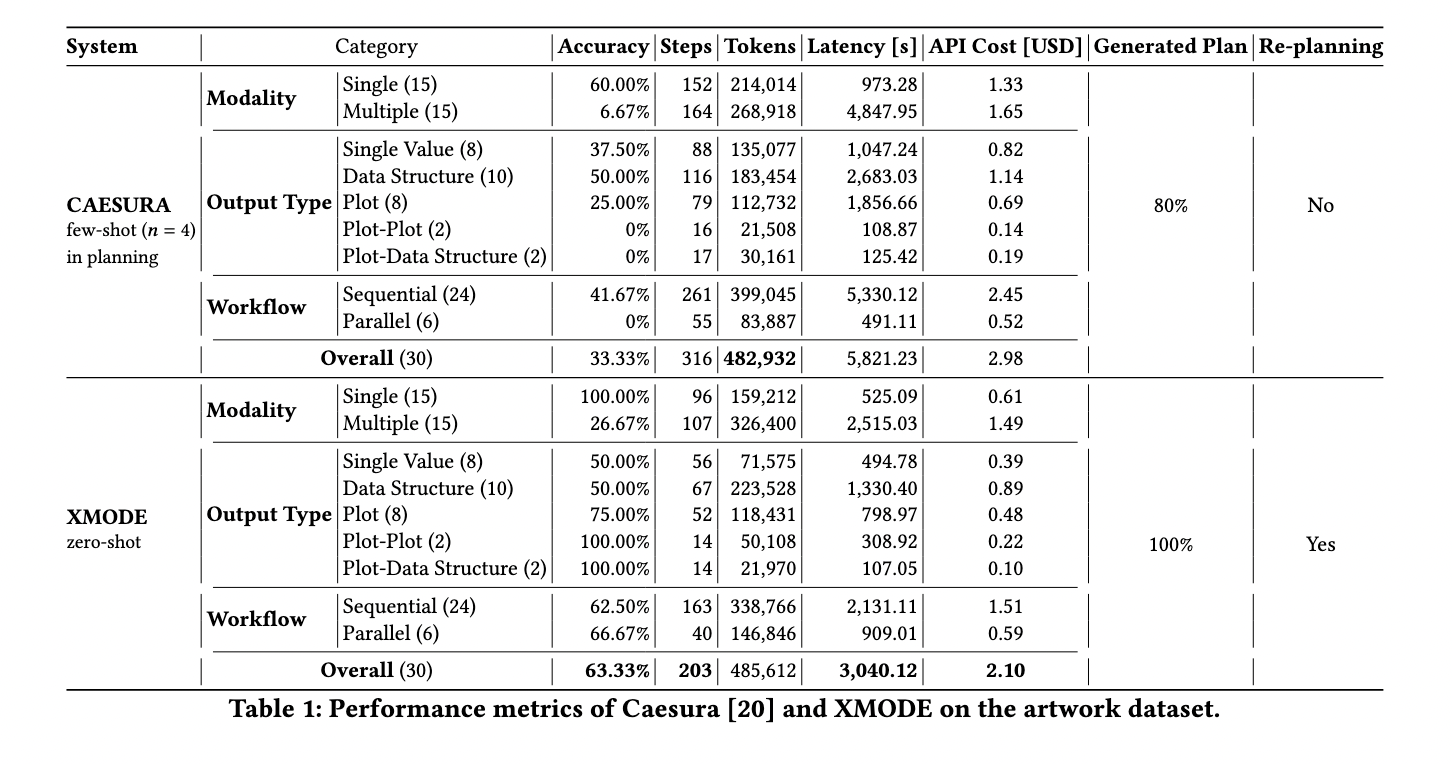
XMODE demonstrated superior efficiency throughout testing on two datasets. On an art work dataset, XMODE achieved 63.33% accuracy general, in comparison with CAESURA’s 33.33%. It excelled in dealing with duties requiring advanced outputs, corresponding to plots and mixed information buildings, attaining 100% accuracy in producing plot-plot and plot-data construction outputs. Additionally, XMODE’s capacity to execute duties in parallel decreased latency to three,040 milliseconds, in comparison with CAESURA’s 5,821 milliseconds. These outcomes spotlight its effectivity in processing pure language queries over multi-modal datasets.
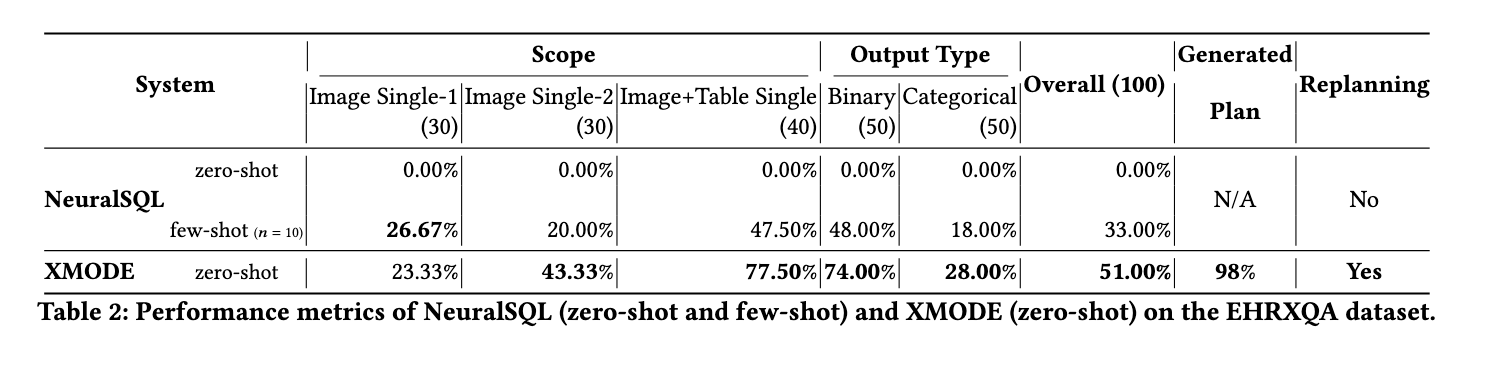
On the digital well being information (EHR) dataset, XMODE achieved 51% accuracy, outperforming NeuralSQL in multi-table queries, scoring 77.50% in comparison with NeuralSQL’s 47.50%. The system demonstrated sturdy efficiency in dealing with binary queries, attaining 74% accuracy, considerably increased than NeuralSQL’s 48% in the identical class. XMODE’s functionality to adapt and re-plan duties contributed to its strong efficiency, making it notably efficient in situations requiring detailed reasoning and cross-modal integration.
XMODE successfully addresses the restrictions of present multi-modal information exploration programs by combining superior planning, parallel process execution, and dynamic re-planning. Its progressive strategy permits customers to question advanced datasets effectively, making certain transparency and explainability. With demonstrated accuracy, effectivity, and cost-effectiveness enhancements, XMODE represents a big development within the discipline, providing sensible purposes in areas corresponding to healthcare and artwork curation.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


{kind=link}